Neste ano, o Likedin iniciou a publicação de seus artigos colaborativos gerados por IA. Trata-se de uma nova vertente da rede social que permite que especialistas de diferentes áreas contribuam com insights para artigos de determinado nicho profissional. Os artigos são iniciados por uma IA, que gera um tópico e um conjunto de perguntas. Em seguida, a IA seleciona um grupo de especialistas relevantes para o tópico, que são convidados a responder às perguntas e contribuir com suas perspectivas e experiências nestes artigos.
O que são os Artigos Colaborativos do LikedIn ?
Os artigos colaborativos foram lançados em Março de 2023, como parte de uma iniciativa do LinkedIn para promover o compartilhamento de conhecimento e colaboração entre profissionais. A IA é usada para facilitar o processo de iniciação de discussões e seleção de especialistas, tornando mais fácil para os profissionais se envolverem em conversas significativas.
Os artigos colaborativos podem ser uma excelente maneira para obter insights de especialistas de diferentes áreas, bem como para se conectar com outros profissionais que compartilham dos mesmos interesses. Estes artigos também podem ser uma forma eficaz de promover expertise e gerar visibilidade para seu perfil.
Alguns exemplos de Artigos:
Gerenciamento de Projetos: https://www.linkedin.com/showcase/skills-project-management/posts/?feedView=articles
Gerenciamento de Programas: https://www.linkedin.com/showcase/skills-program-management/posts/?feedView=articles
Gerenciamento de Riscos: https://www.linkedin.com/showcase/skills-risk-management/posts/?feedView=articles
Por que estes artigos são excelentes fontes para Análise de Dados ?
Este artigos, devido aos profissionais que são selecionados e convidados para contribuirem, passam a ser uma excelente fonte de dados sobre engajamento real de determinado nicho profissional, já que o público é totalmente vinculado aos tópicos dos artigos e com um alto grau de expertise sobre os temas. Medir o engajamento de profissionais qualificados em temas de sua área eleva a acurácia sobre o que de fato gera interesse em profissionais de determinada área, ou seja, fica mais fácil responder à pergunta: Quais são os assuntos nestes artigos que mais despertam interesse em contribuir por estes profissionais ?
Exemplo de convites enviados pelo LinkedIn aos especialistas:

Extraindo dados de engajamento em Artigos Colaborativos do Linkedin
É muito importante, antes de pensar em extrair dados do Linkedin, estar ciente da necessidade de seguir os termos definidos na Política de Privacidade de Dados e Termo de Uso do Linkedin. Os benefícios promovidos pelo Linkedin no engajamento profissional e as diversas oportunidades de seguimento às demandas em nossos nichos de atuação são incontáveis.
Por isso, o respeito às normas definidas pela plataforma, que consegue manter um controle coeso e gerar valor aos seus mais de 930 milhões de usuários, é imprescindível. Neste artigo, não violaremos qualquer Política aplicada pelo Linkedin aos usuários.
Teremos um objetivo principal, com base a dois critérios bem definidos, solicitaremos ao ChatGPT que nos indique títulos de potencial engajamento com base nestes dois critérios que informaremos através do prompt. Para isso utilizaremos um script Python bastante simples.
Os dois critérios que utilizaremos: Um de nossos objetivos será selecionar os títulos que possuem maior engajamento, a partir de 50 contribuições, identificar as palavras que aparecem nestes títulos assim como a frequência em que aparecem nos títulos. Contabilizaremos também os pronomes, conectores, interseções, o motivo é simples: A semântica utilizada para construção do título influencia no engajamento.
Por exemplo, fazer um questionamento ao leitor, induzindo que ele participe com sua experiência na resposta à pergunta exposta no título, tem se mostrado mais eficiente que simplesmente apresentar soluções conhecidas para determinado problema.
O outro critério é simplesmente contextualizar o ChatGPT sobre sugerir títulos também com base nos títulos com maior engajamento, contextualizando a plataforma da Openai sobre a necessidade de utilizar como referência os parâmetros identificados e informados através do Script. Vamos lá!
Importando as classes e funções que utilizaremos:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
import openai
import pyautogui as tempoEspera
import reDefinindo e Instanciando o Navegador que utilizaremos para exibir os dados que iremos extrair do Linkedin:
servico = Service(ChromeDriverManager().install())
navegador = webdriver.Chrome(service=servico)Abrindo o Site que nos servirá de base para extrair os dados
O site que utilizaremos de base para extrair os títulos e número de contribuições é a página sobre Gerenciamento de Projetos do Linkedin, a página será ordenada pelos itens mais recentes: https://www.linkedin.com/showcase/skills-project-management/posts/?feedView=all
Observe que esta página apresenta a lista de Artigos e o número de contribuições em cada.
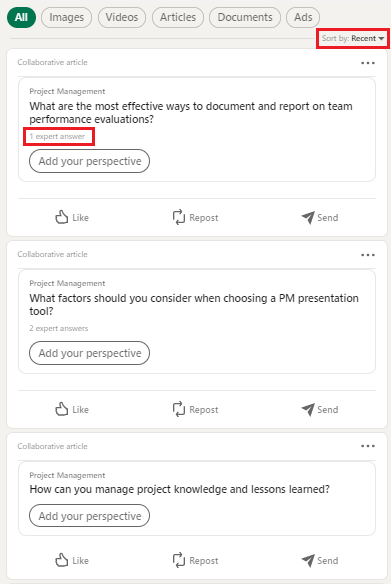
Uma dica: Para nossa sorte e em respeito aos seus usuários, o Linkedin possui políticas de segurança muito bem definidas e criteriosas para autenticações de usuários e confirmação de identidade. Por isso, não costumo acessar o Site do Linkedin diretamente a partir do Script. Prefiro baixar a página como um arquivo .html e acessá-lo diretamente em meu container ou computador.
#Abre o site.
navegador.get("file:///projeto.html")Seleciona o componente da estrutura do Site que utilizaremos para delimitar as informações de Título e número de contribuições.
#Aguarda um tempo para que o computador consiga processar as informações
tempoEspera.sleep(3)
#Seleciona o componente da estrutura do Site que utilizaremos para delimitar as informações de Título e número de contribuições. Destes títulos, selecionaremos os que possuem mais de 50 contribuições.
elemetoTabela = navegador.find_elements(By.XPATH,"//a[contains(@class, 'app-aware-link')]")Selecionando os títulos de artigos do Linkedin que possuem a partir de 50 contribuições
# Selecionando os títulos de artigos do Linkedin que possuem a partir de 50 contribuições.
strM = ''
for linhaAtual in elemetoTabela:
if linhaAtual != '':
# Aguarda um tempo para que o computador consiga processar as informações
tempoEspera.sleep(1)
if ("ManagementProject Management" not in linhaAtual.text) and ("w • " not in linhaAtual.text):
valorAntigo = linhaAtual.text
# Este tratamento poderia ser mais bonito e simples utilizando no máximo duas funções, entretanto será mais didático se fizermos passo a passo a extração dos valores.
if ("expert an" in valorAntigo):
novoV = valorB+" "+valorAntigo
comp_t = novoV.replace('Learning Project Management', '')
comp_d = comp_t.replace('by Project Management Add your perspective', '')
titulo = comp_d.splitlines()[1]
qtde_st = comp_d.splitlines()[2]
qtde_st1 = qtde_st.split('expert answer')
qtde_ct = qtde_st1[0].replace('s', '')
qtde_ct1 = qtde_ct.replace(' ', '')
qtde_int = qtde_ct1
titulo_qtde = titulo+";"+qtde_ct1
if qtde_int.isdigit():
if int(qtde_ct1) >= 50:
print (titulo_qtde)
strM += " "+titulo
valorB = linhaAtual.text
strM2 = strM.replace('?', '')Extraindo as palavras presentes nos títulos com grande engajamento e verificando a frequência em que as palavras aparecem nestes títulos
frequency = {}
match_pattern = re.findall(r'\b[a-z]{3,15}\b', strM2)
for word in match_pattern:
count = frequency.get(word, 0)
frequency[word] = count + 1
word_freq = ''
frequency_list = frequency.keys()
for words in frequency_list:
#print(words, frequency[words])
word_freq += words+': '+str(frequency[words])+' ;'Criação do Prompt para envio ao ChatGPT
# Abaixo está o prompt que enviaremos ao ChatGPT
# Contextualizando o Chatgpt sobre a informação que gostaríamos de receber a partir dos dados que estamos enviando. Solictamos, inclusive, ao ChatGPT que nos envie uma confirmação sobre o entendimento da organização de dados que enviamos através do Prompt.
# Eviaremos ao chatGPT as palavras e as quantidades que aparecem nos títulos dos artigos e exemplos de títulos a partir de 50 contribuições
# A partir destas informações, esperaremos o envio pelo ChatGPT de sugestões de títulos, com base nas informações enviadas, que poderão gerar grande engajamento dos leitores.
q1 = 'Olá! sou gerente de projetos e autor de artigos sobre gerenciamento de projetos. Fiz um levantamento para identificar quais palavras são mais utilizadas em títulos de artigos com grande engajamento com os leitores.'
q2= ' A seguir estão as palavras que são mais utilizadas em títulos de artigos com grande engajamento. A lista a seguir possui as palavras seguidas das quantidades de vezes que apareceram nos títulos de artigos com grande engajamento.'
q3 = ' As palavras e quantidades são separados por dois pontos, :, e as plavras são separadas por ponto e vírgula ;. Veja a lista a seguir: '+word_freq
q4 = ' Também fiz um levantamento dos títulos que mais geram engajamento dos leitores com os artigos. A seguir estão alguns exemplos: '+strM
q5 = ' Com base nas informações acima, preciso que você me retorne duas coisas: 1 - As três primeiras Palavras e quantidades mencionadas acima ordenadas pela quantidade, do maior para o menor, com o objetivo de confirmar que você realmente entendeu o contexto. '
q6 = 'A segunda informação que preciso com base nas informações enviadas acima é: 2 - poderia gerar sugestões de títulos, em português, para artigos com potencial de gerar grande engajamento com base nas palavras que aparecem nos títulos de maior engajamento enviadas acima e com base nos exemplos de títulos de artigos de grande engajamento mostrados anteriormente ?'
qT = q1+q2+q3+q4+q5+q6API para integração com ChatGPT
Para utilização da API para integração é necessário que tenhamos em mãos uma chave para utilização da API. Esta chave é obtida nas definições de usuários do Openai, aqui!
#chave da API do OPENAI para integração do nosso script ao ChatGPT.
openai.api_key = 'sk-...SUA_API'
#Função para integração ao ChatGPT
def chat_with_chatgpt(prompt, model="text-davinci-003"):
response = openai.Completion.create(
engine=model,
prompt=prompt,
max_tokens=2500,
stop=None,
)
message = response.choices[0].text.strip()
return message
Perguntando ao ChatGPT e imprimindo a resposta
user_prompt = qT
chatbot_response = chat_with_chatgpt(user_prompt)
# Exibição da resposta do ChatGPT.
print('Reposta do ChatGPT')
print(chatbot_response)O prompt gerado pelo Script e enviado ao ChatGPT é algo como a seguir:
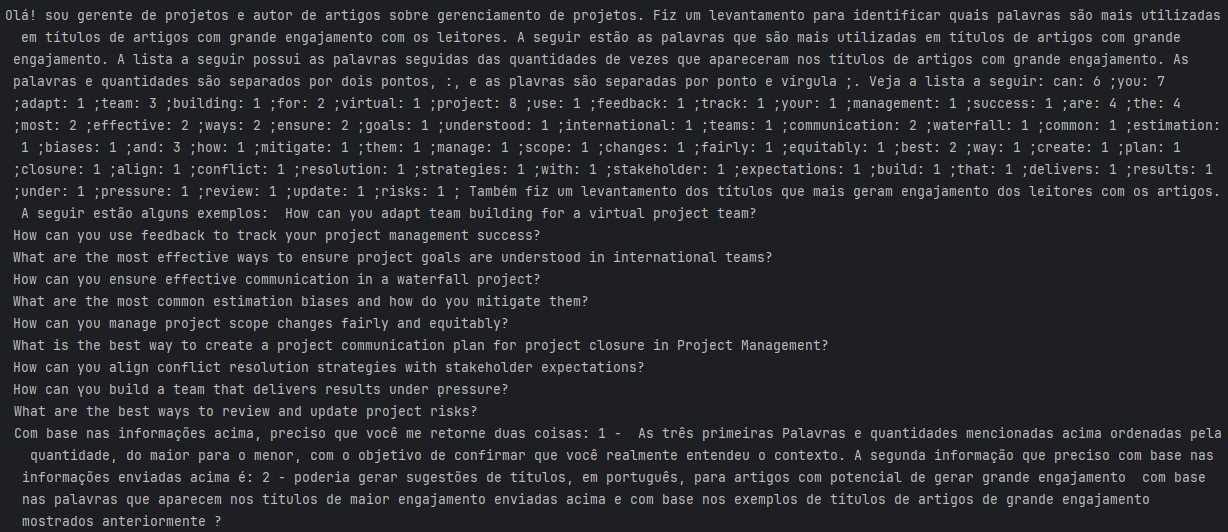
Resposta gerada pelo Script a partir do ChatGPT
Identificação e lista de Títulos, além das quantidades de contribuições:
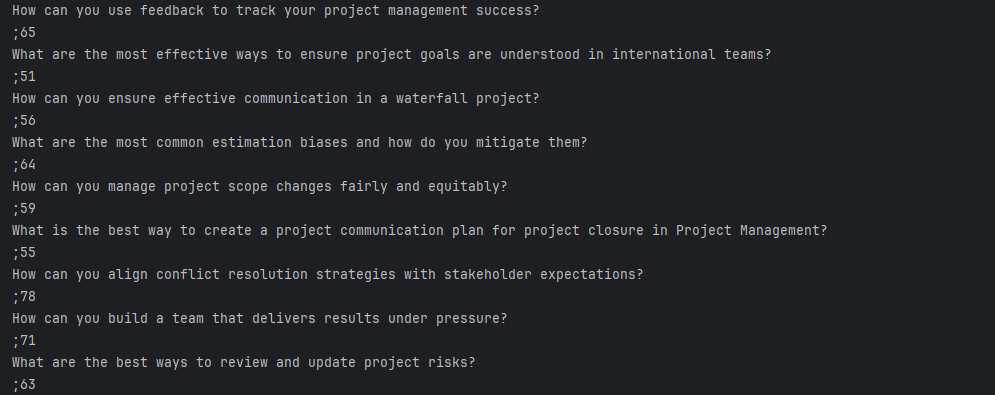
Confirmação pelo ChatGPT que entendeu a demanda e respondendo com as três primeiras palavras enviadas anteriormente seguida da frequência em que aparecem nos títulos:

Por fim, a lista de sugestão de Títulos para artigos com base nas palavras que aparecem nos títulos do Linkedin, frequência em que estas palavras aparecem, número de contribuições e exemplos de títulos a partir de 50 contribuições:

Além disso, o script também imprime o prompt que poderá ser utilizado em outras plataformas de IA generativa, como o Bard, do Google.
Código Completo
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
import openai
import pyautogui as tempoEspera
import re
# Definindo e Instanciando o Navegador que utilizaremos para exibir os dados que iremos extrair do Linkedin.
servico = Service(ChromeDriverManager().install())
navegador = webdriver.Chrome(service=servico)
#Abre o site.
navegador.get("file:///projeto.html")
#Aguarda um tempo para que o computador consiga processar as informações
tempoEspera.sleep(3)
#Seleciona o componente da estrutura do Site que utilizaremos para delimitar as informações de Título e número de contribuições. Destes títulos, selecionaremos os que possuem mais de 50 contribuições.
elemetoTabela = navegador.find_elements(By.XPATH,"//a[contains(@class, 'app-aware-link')]")
# Selecionando os títulos de artigos do Linkedin que possuem a partir de 50 contribuições.
strM = ''
for linhaAtual in elemetoTabela:
if linhaAtual != '':
# Aguarda um tempo para que o computador consiga processar as informações
tempoEspera.sleep(1)
if ("ManagementProject Management" not in linhaAtual.text) and ("w • " not in linhaAtual.text):
valorAntigo = linhaAtual.text
# Este tratamento poderia ser mais bonito e simples utilizando no máximo duas funções, entretanto será mais didático se fizermos passo a passo a extração dos valores.
if ("expert an" in valorAntigo):
novoV = valorB+" "+valorAntigo
comp_t = novoV.replace('Learning Project Management', '')
comp_d = comp_t.replace('by Project Management Add your perspective', '')
titulo = comp_d.splitlines()[1]
qtde_st = comp_d.splitlines()[2]
qtde_st1 = qtde_st.split('expert answer')
qtde_ct = qtde_st1[0].replace('s', '')
qtde_ct1 = qtde_ct.replace(' ', '')
qtde_int = qtde_ct1
titulo_qtde = titulo+";"+qtde_ct1
if qtde_int.isdigit():
if int(qtde_ct1) >= 50:
print (titulo_qtde)
strM += " "+titulo
valorB = linhaAtual.text
strM2 = strM.replace('?', '')
# Extraindo o número de palavras presentes nos títulos e verificando as palavras que se repetem.
frequency = {}
match_pattern = re.findall(r'\b[a-z]{3,15}\b', strM2)
for word in match_pattern:
count = frequency.get(word, 0)
frequency[word] = count + 1
word_freq = ''
frequency_list = frequency.keys()
for words in frequency_list:
#print(words, frequency[words])
word_freq += words+': '+str(frequency[words])+' ;'
# Abaixo está o prompt que enviaremos ao ChatGPT
# Contextualizando o Chatgpt sobre a informação que gostaríamos de receber a partir dos dados que estamos enviando. Solictamos, inclusive, ao ChatGPT que nos envie uma confirmação sobre o entendimento da organização de dados que enviamos através do Prompt.
# Eviaremos ao chatGPT as palavras e as quantidades que aparecem nos títulos dos artigos e exemplos de títulos a partir de 50 contribuições
# A partir destas informações, esperaremos o envio pelo ChatGPT de sugestões de títulos, com base nas informações enviadas, que poderão gerar grande engajamento dos leitores.
q1 = 'Olá! sou gerente de projetos e autor de artigos sobre gerenciamento de projetos. Fiz um levantamento para identificar quais palavras são mais utilizadas em títulos de artigos com grande engajamento com os leitores.'
q2= ' A seguir estão as palavras que são mais utilizadas em títulos de artigos com grande engajamento. A lista a seguir possui as palavras seguidas das quantidades de vezes que apareceram nos títulos de artigos com grande engajamento.'
q3 = ' As palavras e quantidades são separados por dois pontos, :, e as plavras são separadas por ponto e vírgula ;. Veja a lista a seguir: '+word_freq
q4 = ' Também fiz um levantamento dos títulos que mais geram engajamento dos leitores com os artigos. A seguir estão alguns exemplos: '+strM
q5 = ' Com base nas informações acima, preciso que você me retorne duas coisas: 1 - As três primeiras Palavras e quantidades mencionadas acima ordenadas pela quantidade, do maior para o menor, com o objetivo de confirmar que você realmente entendeu o contexto. '
q6 = 'A segunda informação que preciso com base nas informações enviadas acima é: 2 - poderia gerar sugestões de títulos, em português, para artigos com potencial de gerar grande engajamento com base nas palavras que aparecem nos títulos de maior engajamento enviadas acima e com base nos exemplos de títulos de artigos de grande engajamento mostrados anteriormente ?'
qT = q1+q2+q3+q4+q5+q6
qT1 = q1+q2+q3+q4
qT2 = q5
qT3 = q6
#chave da API do OPENAI para integração do nosso script ao ChatGPT.
openai.api_key = 'sk-suaAPI'
#Função para integração ao ChatGPT
def chat_with_chatgpt(prompt, model="text-davinci-003"):
response = openai.Completion.create(
engine=model,
prompt=prompt,
max_tokens=2500,
stop=None,
)
message = response.choices[0].text.strip()
return message
user_prompt = qT
chatbot_response = chat_with_chatgpt(user_prompt)
# Exibição da resposta do ChatGPT.
print('------------')
print(' ')
print('Reposta do ChatGPT')
print(' ')
print('(O ChatGPT retornará duas respostas. A primeira é apenas a confirmação que entendeu a formatação dos dados enviados. Serão retornados três exemplos de palavras seguidas pela frequência de aparição. A segunda resposta trata-se da sugestão de Títulos com base nas informações de relevância enviadas anteriormente.)')
print('------------')
print(' ')
print('Confira a Resposta a seguir:')
print('')
print(chatbot_response)
# Você também pode utilizar o mesmo prompt enviado ao ChatGPT no BARD, do Google.
print('------------')
print ('')
print('Este Script está integrado apenas ao ChatGPT, você pode utilizar o mesmo prompt para realizar a mesma consulta ao BARG. Utilize o prompt a seguir:')
print('')
print (qT)